














WIKIDATA
Knowledge Graphs based on Linked Open Data
Goals
The Wikimedia Foundation's Wikidata project aims at building a free linked database providing the data contained in Wikipedia in a structured, machine-processable format. Seen in the broader scope of knowledge graphs being built and used by other large companies such as Google, Facebook, or LinkedIn, the Wikidata knowledge graph allegorically typifies the emerging trend from a Web of Documents to a Web of Data, in which computers are enabled to understand and leverage the knowledge previously hidden behind unstructured Web pages.
Since the official launch of the Wikidata project in 2012, the Wikidata community has gathered and stored several hundred millions of cross-domain knowledge facts about persons, places, artifacts, terms, links to Wikipedia pages, and many more. Facts include both temporal as well as spatial information, are often annotated with provenance information (e.g., the articles or statistical data they have been extracted from), and - with Wikidata being laid out as an international project - may be represented in multiple languages.
metaphacts' Role in the Wikidata Project
As the Wikidata knowledge graph is not only a prototypical example but also a valuable resource for the community, metaphacts is working in close cooperation with the Wikimedia Foundation to help others utilize the knowledge that is created within the Wikidata project. Leveraging our platform metaphactory and its extensible, easy-to-use components and services, metaphacts offers a full-fledged portfolio for interacting with and managing open knowledge graphs such as Wikidata and building applications on top.
Building Applications on top of the Wikidata Query Service
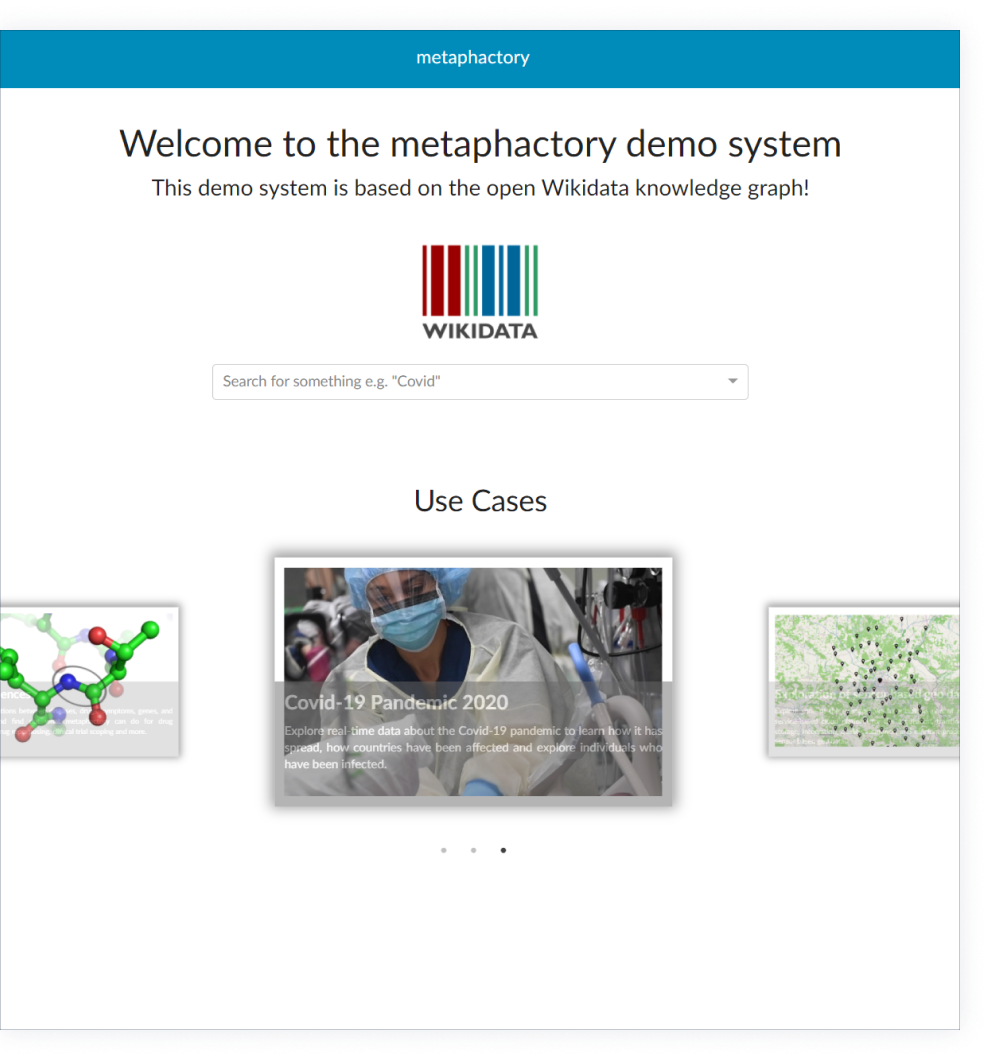
With metaphactory, we provide a generic platform that allows customers to access the Wikidata free corpus of structured knowledge and seamlessly integrate their enterprise data with open data, thus being able to contextualize their internal knowledge and build own, customized applications on top.
Using metaphactory, we have set up a public demo system for the community, easing access to the information provided by the Wikidata query service. The system provides different search interfaces as entry points into Wikidata's knowledge base and visualizes search results based on a comprehensive HTML5 based templating approach.
Internally, the metaphactory approach is based on reusable Web Components enabling accelerated application development. It includes services and UIs for data integration and curation, as well as components for visualizing and exploring the knowledge graph's data. Examples include a table and a graph view over the data, as well as options for interactive faceted exploration of item collections. Additionally, the solution offers customizable hybrid semantic search components exploiting both structured query answering as well as fulltext keyword search.
Who is this relevant for?
With metaphactory, metaphacts delivers a generic platform with extensible, easy-to-use components and services for interacting with and leveraging the Wikidata knowledge graph query service. These components and services are relevant for various other industries - such as the healthcare and life sciences sector, the financial sector, governmental agencies - and their functionalities can be easily transferred to other application areas.
One concrete example is our data-driven geomarketing use case, where Twitter feeds are semantically analyzed, linked to Wikidata entities, and thereby contextualized, allowing small and medium-sized businesses and retailers to link sensor data with Social Media and Open Data, so as to improve their advertising and marketing strategies.